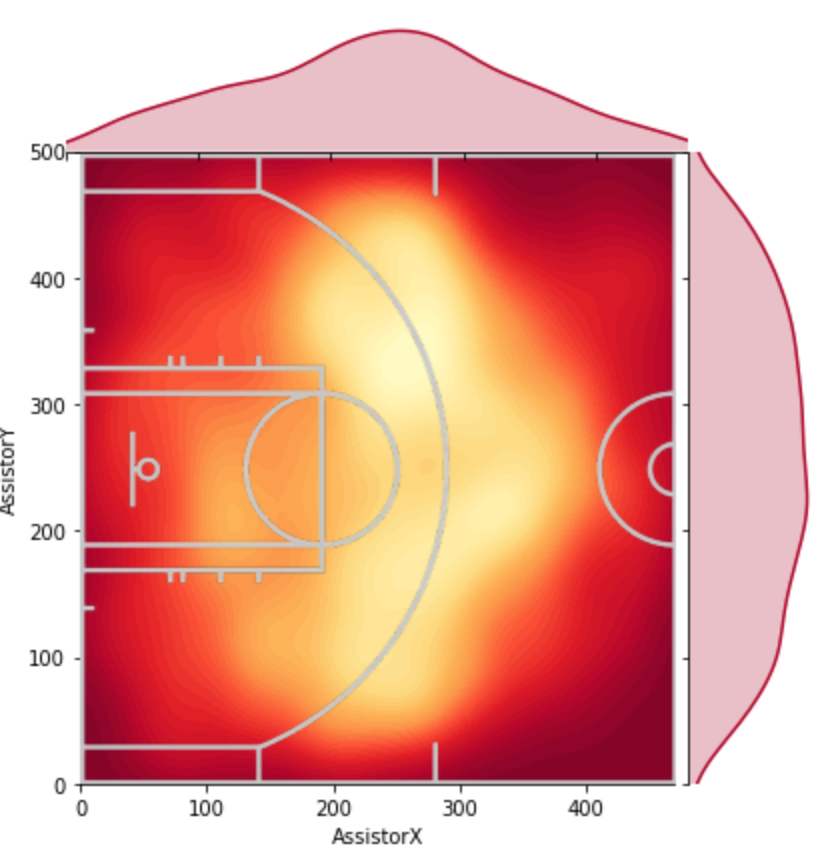
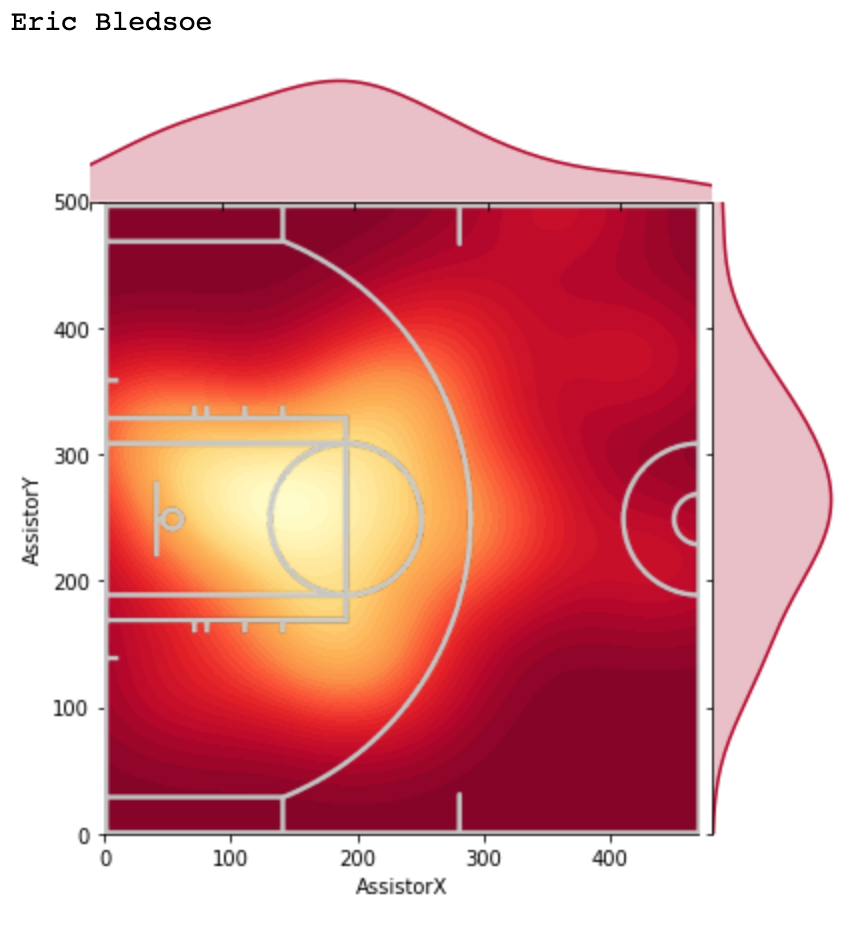
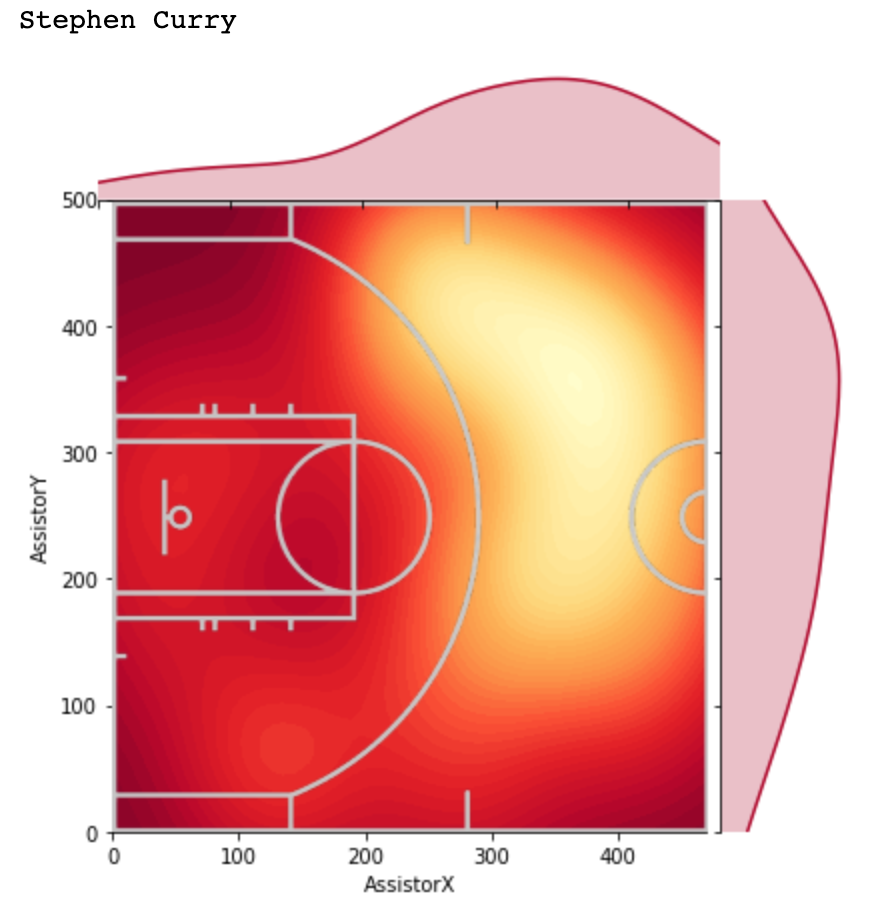
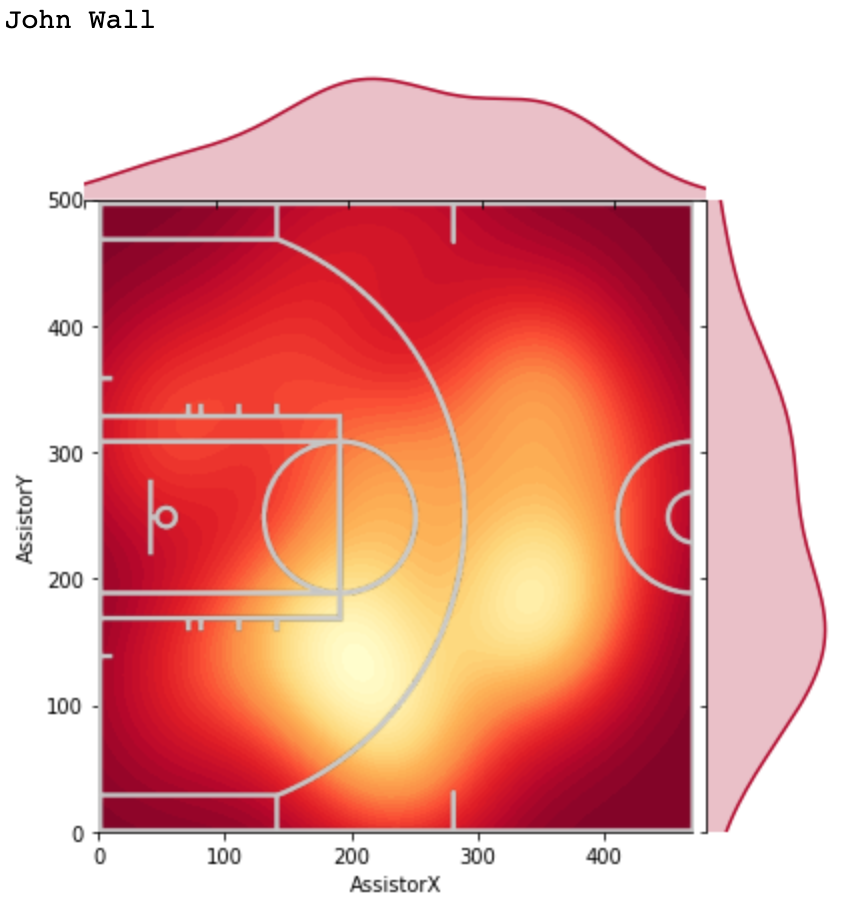
It’s been a while since I’ve done an NBA analytics project, but I’ve recently been intrigued by player-player interactions within teams. Oftentimes, fans have a hunch that two players “mesh” well together or two players’ playstyles do not complement one another. However, for the most part, this is a qualitative observation. In this article, I will present a simple, quantitative way of discovering favorable/unfavorable duos in the NBA (in addition to investigating specific duos).
Simple concepts
The concepts discussed in this article come from biology. Specifically, in ecology, the term symbiosis refers to the relationship between two different species. These relationships can take many forms – mutualism (both species benefit), parasitism (one species benefits, the other species is harmed), commensenalism (one species benefits, the other species is neither harmed nor benefitted), neutralism (neither species is affected), and competition (both species are negatively affected).

When talking about basketball, we are no longer talking about biological species but rather interactions between two players in a lineup. For instance, a mutualistic relationship would be a relationship which having two players in a lineup is more efficient than than having one or the other. If we are appropriately able to single out such mutualistic relationships (and discover which players do not mesh well together i.e with a competitive relationship), this is a useful tool for coaches when building lineups.
Quantifying Symbiosis
In order to quantify the relationships between players, I follow a very simple process. Let us assume that we are attempting to quantify the symbiotic relationship between player A and player B on a given team X. We will sort lineups for team X into 4 categories:
- lineups with player A but not player B,
- lineups with player B but not player A,
- lineups with both player A and player B, and
- lineups with neither player A or player B.
We can then calculate net rating for categories 1, 2, and 3. If the net rating of category 3 is greater than the net rating of categories 1 and 2, then this is a mutualistic relationship (a favorable duo to play together). Through this simple process, we can determine the relationship between any two given players on a team. Although this process is not perfect, it potentially could give us an indication of how duos play together. A potential problem with this approach is that if the replacement player in a lineup for a given player B is significantly worse than player B, this would exaggerate the benefit of adding player B to a lineup with player A.
There is also the issue of multicollinearity. Since a lineup consists of 5 players, it is impossible to control for context, and there might be additional players affecting these numbers.
Distribution of Duos
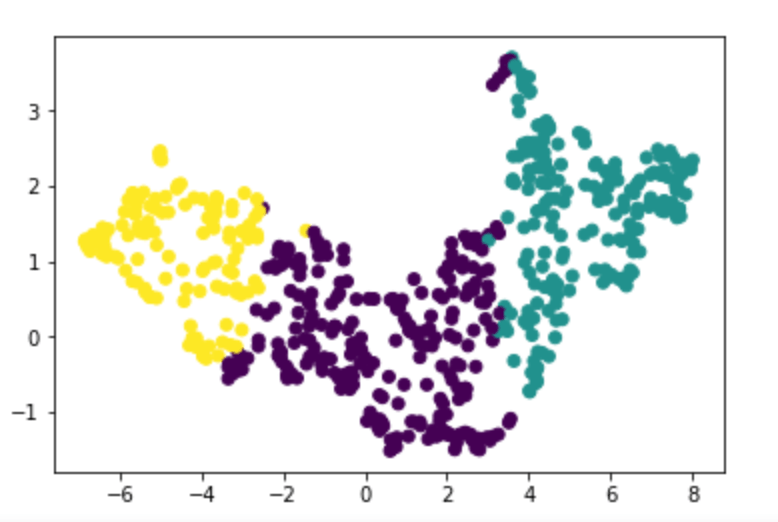
We begin our analysis by calculating values for every given duo in the NBA (such that they have played at least 400 minutes together and 400 minutes apart). This leaves us with 672 duos in the league.

In the above graph, we first note that the upper right corner is mutualistic duos, while the bottom left is competitive duos (duos that do not play well together). The other two quadrants represent duos where one player is positively affected while the other player is negatively affected.
The first thing that I found interesting was the correlation between the two variables in the plot (Spearman correlation was 0.44). Our correlation shows us that there is a moderate linear relationship between our two variables (meaning that if player A impacts lineups with player B negatively, we have a general idea that player B may negatively affect lineups with player A).
Interactions within Teams
Phoenix Suns

In this graph, each box represents the net rating change when adding Player B to a Lineup with player A (a white box represents a duo which we do not have enough minutes of). To understand what this means, we will ask a question: How do lineups with Chris Paul and DeAndre Ayton compare to lineups with just Chris Paul (and not DeAndre Ayton)?
With the phrasing of this question, player A is Chris Paul and player B is DeAndre Ayton. The value is then -7.2. What does this mean? A Suns lineup with Chris Paul and not DeAndre Ayton is more favorable than a lineup with both Chris Paul and DeAndre Ayton by approximately 7.2 points per 100 possessions. Similarly, if we look at lineups with just DeAndre Ayton and not Chris Paul (player A is DeAndre Ayton now), the value is -7.4: again unfavorable.
Surprisingly, the symbiotic relationship between Chris Paul and DeAndre Ayton seems to be competitive. This result seemed somewhat counterintuitive to me.
Thus, I decided to delve a bit deeper. Based on data from pbpstats.com (great resource), lineups with both Chris Paul and DeAndre Ayton have a net rating of 6.93 on average. However, when on lineups separately, Paul and Ayton’s lineups have net ratings of 13.27 and 12.46, respectively.

This could very well be an artifact, but it still remains an interesting result to investigate further.
On more intuitive results from our graph, for the most part Chris Paul has a positive effect when added to lineups. Further, Devin Booker/DeAndre Ayton seem to have a somewhat mutualistic relationship, as do Devin Booker/Chris Paul.
Los Angeles Lakers
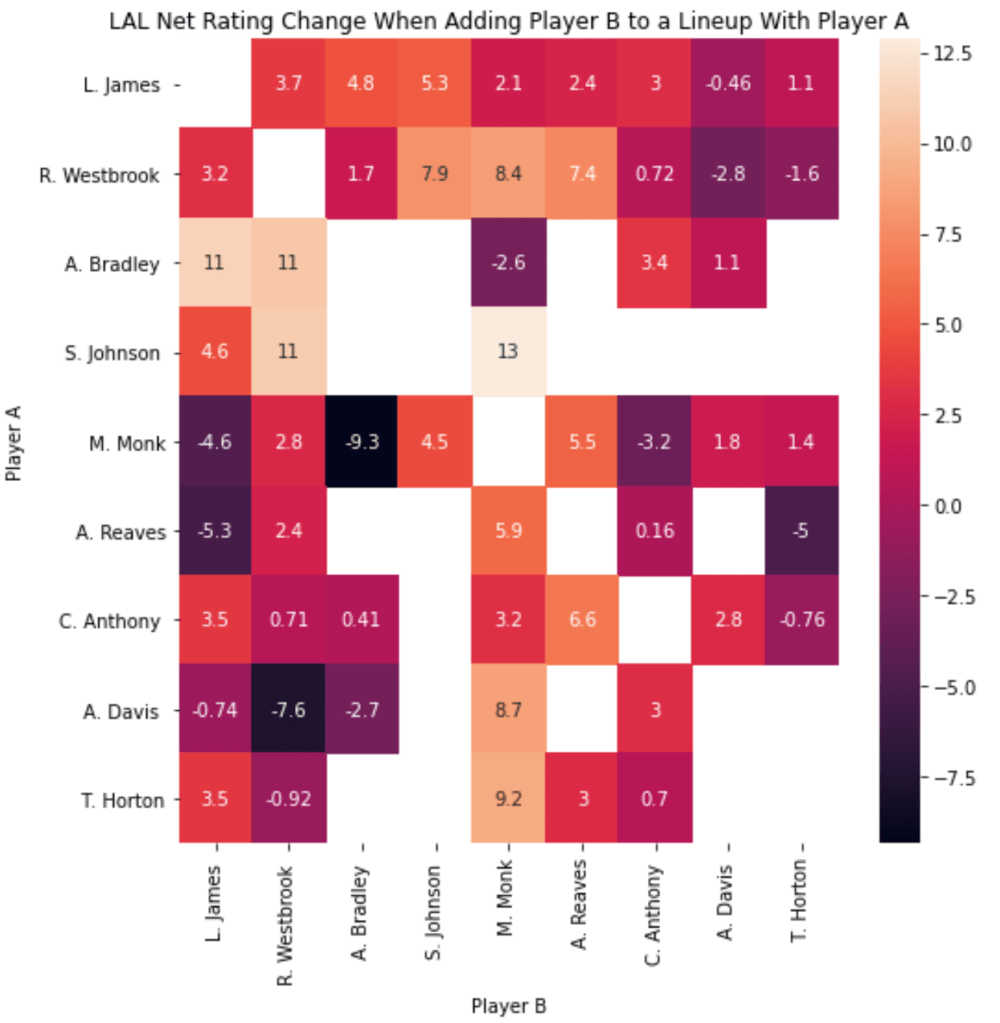
In our graph, we see that Malik Monk and Austin Reaves have a very strong mutualistic relationship with one another. This is a relationship that’s caught the eye of the Lakers coaching staff/front office and was a duo that was used in a big win against the Warriors.
Outside of this duo, interesting duos I found were Malik Monk and Avery Bradley (competitive), Anthony Davis and Russell Westbrook (competitive), Avery Bradley and LeBron James (mutualistic).
Golden State Warriors

For Golden State, some interesting combinations were Steph/Draymond (mutualistic), Steph/Poole (mutualistic). Further, it is clear that the Splash Brother duo hasn’t performed as well as they normally would (although adding Steph to Klay lineups is positive, adding Klay to Steph lineups isn’t improving net rating of those lineups).
Minnesota Timberwolves

The last team we’ll look at is one of the hottest teams in the league right now. Some interesting relationships: KAT/D’Angelo (mutualistic), Anthony Edwards/D’Angelo (mutualistic), Pat Bev/D’Angelo (mutualistic).
Conclusion
I think this is a good preliminary step into better understanding how lineups work together. Although this is a far-from-perfect way of measuing the effectiveness of specific duos in the league, I do think this provides some insight on specific players that mesh well with other specific players, as well as specific players who do not play well with specific players.